1. Aufgabe zum Verständnis von Vererbung
Folgender Code ist gegeben:
public class First {
protected int count;
public First() {
System.out.println("First");
calculate();
}
public void calculate() {
System.out.println(count);
}
@Override
public int hashCode() {
return 0;
}
}
class Second extends First {
public Second() {
this.count = 5;
System.out.println("Second");
calculate();
}
public void calculate() {
this.count++;
System.out.println(count);
}
@Override
public int hashCode() {
return 0;
}
}
class Main {
public static void main(String[] args) {
Second s = new Second();
}
}Antwort:
First
1
Second
6
Anmerkung:
- Bei Erstellung von
Second s = new Second();wird zuerst der Konstruktor der ElternklasseFirstaufgerufen - Im Konstruktor
First()System.out.println("First")- gibt “First” auscalculate()→ ruft die überschriebene Methode aus Klasse “Second” auf
- Dann wird der Konstruktor “Second()” ausgeführt
this.count = 5→ count wird 5System.out.println("Second")→ gibt “Second” auscalculate()→ ruft erneut “Second.calculate()” auf, wo “count++” erfolgt
2. Kenntnis des Vertrags zwischen Equals und HashCode
Es gibt Code (Klassen wie in der obigen Aufgabe), was gibt er aus:
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add(new First());
set.add(new Second());
set.add(new Second());
System.out.println("Größe:" + set.size());
}Antwort:
Größe:3
Anmerkung:
new First()- wird hinzugefügt (hashCode = 0)new Second()- wird überprüft:- HashCode = 0 (stimmt überein)
equals()vergleicht standardmäßig Referenzen → verschiedene Objekte → wird hinzugefügt
new Second()- noch ein neues Objekt:- HashCode = 0 (stimmt überein)
equals()vergleicht Referenzen → dies ist ein drittes einzigartiges Objekt → wird hinzugefügt
Die Methode equals() vergleicht standardmäßig (aus Klasse Object) Referenzen auf Objekte, nicht deren Inhalt. Daher erstellt jedes new Second() ein neues Objekt mit einer neuen Referenz, und alle gelten als verschieden.
Es ist wichtig zu bemerken, dass selbst wenn hashCode nicht übereinstimmen würde, wir trotzdem Größe:3 erhalten
Aber wenn wir equals und hashCode überschreiben:
@EqualsAndHashCode // als Beispiel Annotation von Lombok
public class First {
}
@EqualsAndHashCode
class Second extends First {
}Dann wird das Ergebnis Size:2 sein
3. HashMap-Struktur
Ich verstehe, dass fast überall über HashMap gesprochen wurde. Ich werde sehr kurz erzählen (wenn Sie ausführlicher lesen und vertiefen möchten, können Sie hier schauen)
Antwort:
HashMap — ist ein Array von Buckets. Den Index wählen wir nach hashCode, und Kollisionen lösen wir durch Vergleiche über equals.
Einfügealgorithmus:
- Berechnen hashCode() und bestimmen den Bucket.
- Wenn Bucket leer - einfügen.
- Wenn im Bucket Elemente vorhanden:
- suchen denselben Schlüssel über equals
- wenn gefunden → Wert ersetzen
- wenn nicht → neues Element hinzufügen (Liste → Baum bei >8 Elementen)
- Bei Füllgrad >loadFactor erfolgt resize.
4. Wozu braucht man binäre Bäume und ihre Komplexität
Über binäre Bäume wurde auch schon überall gesprochen, detaillierte Info hier
Antwort:
Wozu binäre Bäume: Um Daten in sortierter Form zu speichern und schnell Suche, Einfügen und Löschen durchzuführen.
Suchkomplexität in BST:
- Bester Fall (ausbalanciert): O(log n)
- Schlechtester Fall (degeneriert zur Liste): O(n)
Einfügekomplexität:
- Bester Fall: O(log n)
- Schlechtester Fall: O(n)
5. Welche GC-Typen gibt es und worin unterscheiden sie sich
Darüber habe ich hier erzählt
Antwort:
Serial GC
- Verwendet einen Thread für alle GC-Phasen.
- Geeignet für Single-Thread-Anwendungen und kleine Heaps.
- Algorithmus: “copying” (in Young Gen) und “mark-sweep-compact” (in Old Gen).
- Parameter:
-XX:+UseSerialGC
Parallel GC (Throughput Collector)
- Verwendet mehrere Threads für Arbeit in Young und Old Gen.
- Ziel — maximaler Durchsatz, nicht Pausenminimierung.
- Geeignet für Serveranwendungen ohne strenge Latenzanforderungen.
- Parameter:
-XX:+UseParallelGC
CMS (Concurrent Mark Sweep) [veraltet]
- Arbeitet parallel zur Anwendung (concurrent), reduziert Stop-the-World-Pausen.
- Phasen: initial mark, concurrent mark, remark, sweep.
- Kompaktiert Speicher nicht (kann zu Fragmentierung führen).
- Veraltet ab Java 9 und entfernt in Java 14
- Parameter:
-XX:+UseConcMarkSweepGC
G1 GC (Garbage First)
- Teilt Heap in viele Regionen.
- Jede Region kann Teil von Young oder Old Generation sein.
- GC-Phasen umfassen: Initial Mark, Concurrent Mark, Remark, Cleanup, Copy.
- Arbeitet nach Prinzip “Sammlung zuerst der müllreichsten Regionen” (Garbage First).
- Verwendet vorhersagbare Pausen und versucht MaxGCPauseMillis nicht zu überschreiten
- Unterstützt inkrementelle, concurrent und kompaktierende Sammlung von Old Gen.
- G1 führt Statistiken über “Nützlichkeit” von Regionen und wählt die effektivsten für Sammlung.
- Parameter:
-XX:+UseG1GC - Standardmäßig verwendet ab Java 9+
ZGC (Z Garbage Collector)
- Unterstützt Heaps bis zu Terabytes.
- Arbeitet mit Pausen unter 10 ms, unabhängig von Heap-Größe.
- Vollständig concurrent (fast alle Phasen parallel zur Anwendung).
- Geeignet für latency-sensitive Systeme.
- Parameter:
-XX:+UseZGC
Shenandoah
- Ähnlich wie ZGC, mit Fokus auf kurze Pausen.
- Verwendet concurrent compacting.
- Unterstützt von OpenJDK.
- Parameter:
-XX:+UseShenandoahGC
6. Referenztypen in Java
Antwort:
Strong Reference (starke Referenz)
- Dies sind normale Referenzen, die wir jeden Tag verwenden.
- Solange mindestens eine starke Referenz auf das Objekt existiert - ist es nicht für Garbage Collection geeignet.
- Damit das Objekt gesammelt werden kann, müssen alle starken Referenzen darauf auf null gesetzt werden.
Object obj = new Object();Soft Reference (weiche Referenz)
- Objekt wird nur bei Speichermangel gelöscht.
- Wird in Caches verwendet, um keinen Speicher zu verbrauchen, aber Objekt zu behalten, wenn es noch nützlich ist.
- Man kann Objekt über
ref.get()erhalten, aber wenn GC es bereits gelöscht hat — wirdnullzurückgegeben.
SoftReference<Object> ref = new SoftReference<>(new Object());Weak Reference (schwache Referenz)
- Objekt kann sofort gesammelt werden, selbst wenn nur schwache Referenzen darauf verbleiben.
- Wird verwendet für Implementierung von Strukturen mit automatischer Löschung (z.B.
WeakHashMap). - Wird oft angewendet, wenn Objekt verfügbar sein sollte “solange es jemand braucht”.
WeakReference<Object> ref = new WeakReference<>(new Object());Phantom Reference (Phantom-Referenz)
- Objekt ist bereits zum Löschen markiert, aber noch nicht vom GC gesammelt.
- Methode
get()gibt immer**null**zurück. - Wird verwendet für Kontrolle der Finalisierung und Freigabe von Ressourcen außerhalb des Heaps (z.B. off-heap, native).
- Erfordert
ReferenceQueue, über die man erfahren kann, dass Objekt bald gelöscht wird.
PhantomReference<Object> ref = new PhantomReference<>(new Object(), referenceQueue);7. Nenne 5 Klassen aus dem concurrent-Paket und wozu sie dienen
Antwort
- CompletableFuture - ermöglicht asynchrone Aufgaben, deren Kombination, Callbacks und Arbeit ohne Blockierungen. Vereinfacht Parallelität.
- ConcurrentHashMap - threadsichere HashMap. Ermöglicht vielen Threads gleichzeitiges Lesen und Aktualisieren von Daten ohne großen gemeinsamen Lock.
- Phaser - fortgeschrittener Synchronizer, ermöglicht Thread-Synchronisation nach Phasen (Etappen). Flexibler als CyclicBarrier/CountDownLatch.
- AtomicInteger - Primitiv für atomare Operationen über int ohne Locks (CAS). Benötigt für Zähler, Flags und Inkremente zwischen Threads.
- ReentrantLock - explizite Sperre mit erweiterten Möglichkeiten: tryLock, Fairness, Condition-Variablen. Flexiblere Alternative zu synchronized.
8. Erzähle über DeadLock und LiveLock
Antwort
Deadlock (gegenseitige Blockierung)
Threads blockieren sich gegenseitig für immer, jeder wartet auf eine Ressource, die vom anderen gehalten wird. Ergebnis: System steht, kein Fortschritt.
Beispiel: Thread A hält Ressource 1 und wartet auf Ressource 2. Thread B hält Ressource 2 und wartet auf Ressource 1.
Wie vermeiden:
- Ressourcen immer in derselben Reihenfolge sperren.
- Timeouts beim Erfassen von Sperren verwenden (tryLock(timeout)).
- Anzahl gleichzeitig erfasster Sperren minimieren.
Livelock (lebendige Blockierung)
Threads sind nicht blockiert, bewegen sich aber nutzlos, versuchen ständig Konflikte zu vermeiden und stören sich gegenseitig. Ergebnis: System arbeitet, aber auch kein Fortschritt.
Beispiel: Zwei Threads geben einander Ressourcen ab, lehnen ab und versuchen erneut, aber synchron und endlos.
Wie vermeiden:
- Zufällige Verzögerungen oder exponentielles Backoff bei wiederholten Versuchen hinzufügen.
- Explizite Timeouts verwenden und Versuche nach bestimmter Zeit beenden.
- Kooperationsalgorithmus überdenken, um sich nicht gegenseitig kontinuierlich zu blockieren.
9. SQL-Aufgabe
Es gibt folgende DB-Struktur:
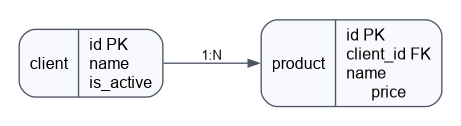 Eine Abfrage schreiben, die Name und Gesamtsumme der Produkte des Kunden zurückgibt. Kunde muss dabei aktiv sein und Produktsumme größer als 0
Eine Abfrage schreiben, die Name und Gesamtsumme der Produkte des Kunden zurückgibt. Kunde muss dabei aktiv sein und Produktsumme größer als 0
Antwort
SELECT c.name AS company_name, SUM(p.price) AS product_sum
FROM client c
JOIN product p ON c.id = p.client_id
WHERE c.is_active
GROUP BY c.id, c.name
HAVING SUM(p.price) > 0
ORDER BY product_sum DESC;10. Worin besteht der Unterschied zwischen having und where
Antwort
Anwendungszeitpunkt
- WHERE - Filterung vor Gruppierung (auf Ebene einzelner Zeilen)
- HAVING - Filterung nach Gruppierung (auf Gruppenebene) Womit arbeiten sie
- WHERE - arbeitet mit einzelnen Datensätzen und normalen Feldern
- HAVING - arbeitet mit Ergebnissen von Aggregatfunktionen (SUM, COUNT, AVG usw.) Verwendung mit GROUP BY
- WHERE - kann ohne GROUP BY verwendet werden
- HAVING - wird zusammen mit GROUP BY verwendet
11. Was ist explain plan und wozu dient er
Antwort
EXPLAIN PLAN — ist ein Ausführungsplan einer SQL-Abfrage, der zeigt, welche Operationen das DBMS ausführen wird (Tabellenscan, Indexverwendung, Join-Typen usw.). Er dient zum Verständnis, wo Engpässe liegen und was optimiert werden kann — zum Beispiel Index hinzufügen, Join-Typ ändern oder Abfrage umschreiben.
12. Welche Transaktions-Isolationsstufen gibt es und welche Probleme existieren in ihnen?
Antwort
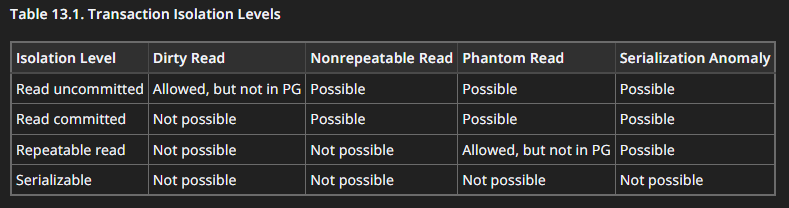 PostgreSQL: Documentation: 18: 13.2. Transaction Isolation
PostgreSQL: Documentation: 18: 13.2. Transaction Isolation
13. Verständnis von Proxy in Spring
Es gibt Basisaufgaben mit Transaktionen, aber in diesem Interview fragte man mich nach @Cacheable. Es gibt ein Codebeispiel, in dem Cache nicht funktioniert, wie macht man es funktionierend:
@Service@EnableCaching
public class CacheClass {
@SneakyThrows
@PostConstruct
public void init() {
System.out.println(test(1));
Thread.sleep(1000);
System.out.println(test(2));
Thread.sleep(1000);
System.out.println(test(1));
}
@Cacheable(cacheNames = "test", key = "#integer")
public String test(int integer) {
return LocalDateTime.now().toString();
}
}Antwort
Hier kann man sofort mehrere Varianten analog zu Transaktionen vorschlagen:
- Self-Inject machen und Methode darüber aufrufen
- applicationContext.getBean(CacheClass.class) verwenden Für @Transaction würde dies 100% funktionieren, aber in Cacheable gibt es einen Fallstrick. Keine der oberen Varianten funktioniert. Denk noch, wie man dies lösen kann?
Antwort für Cacheable
Für @Cacheable ist die Situation noch schlimmer: Cache-Aspekt initialisiert später, daher funktioniert Aufruf von @Cacheable aus @PostConstruct normalerweise nicht — darüber gibt es explizites Issue in Spring
Hier können Sie ApplicationRunner oder CommandLineRunner anwenden, die helfen können, einfach implementieren:
@Service
@EnableCaching
public class CacheClass implements ApplicationRunner {
@Autowired
@Lazy
private CacheClass self;
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println(self.test(1));
Thread.sleep(1000);
System.out.println(self.test(2));
Thread.sleep(1000);
System.out.println(self.test(1));
}
@Cacheable(cacheNames = "test", key = "#integer")
public String test(int integer) {
return LocalDateTime.now().toString();
}
}14. Geben Sie ein Beispiel für jeden Mustertyp (Verhaltens-, Erzeugungs-, Strukturmuster) und nennen Sie Ihr Lieblingsmuster und wie Sie es angewendet haben.
Antwort
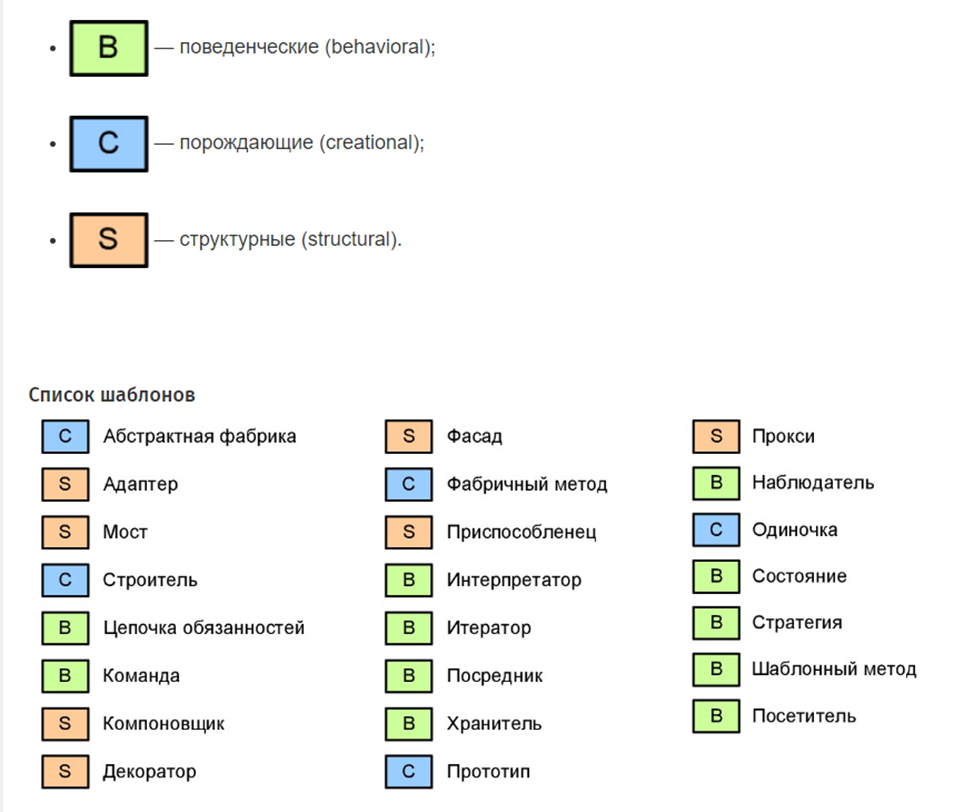 Mein Lieblingsmuster ist Template Method. Template Method wird verwendet, wenn es einen allgemeinen Algorithmus gibt, der sich bei verschiedenen Handlern wiederholt, aber einige Schritte darin müssen unterschiedlich sein. Die allgemeine Logik wird in der Basisklasse fixiert, und die sich ändernden Teile werden in abstrakte Methoden ausgelagert, und konkrete Implementierungen bestimmen, was in diesen Etappen passiert. Dies vermeidet Code-Duplizierung und trennt klar allgemeine und unterschiedliche Algorithmusschritte.
Dieses Muster hat mich mehr als einmal gerettet)
Mein Lieblingsmuster ist Template Method. Template Method wird verwendet, wenn es einen allgemeinen Algorithmus gibt, der sich bei verschiedenen Handlern wiederholt, aber einige Schritte darin müssen unterschiedlich sein. Die allgemeine Logik wird in der Basisklasse fixiert, und die sich ändernden Teile werden in abstrakte Methoden ausgelagert, und konkrete Implementierungen bestimmen, was in diesen Etappen passiert. Dies vermeidet Code-Duplizierung und trennt klar allgemeine und unterschiedliche Algorithmusschritte.
Dieses Muster hat mich mehr als einmal gerettet)
15. Wann relationale Datenbanken verwenden und wann nicht. Worin besteht der Unterschied zwischen SQL- und NoSQL-Datenbank
Antwort
SQL DB:
- Komplexe Abfragen und JOIN — wenn Aggregationen und Beziehungen zwischen Tabellen benötigt werden
- ACID-Transaktionen — Bankoperationen, Finanzsysteme
- Strukturierte Daten — klares Schema, vorhersagbare Struktur
- Datenintegrität — Fremdschlüssel, Constraints
- Reporting und Analytik — komplexe SQL-Abfragen Geeignet für: Banksysteme (Transaktionen), medizinische Aufzeichnungen (Datenintegrität), Online-Shops (Bestellungen, Inventory)
NoSQL DB:
- Große Datenmengen — Big Data, Logging
- Horizontale Skalierung — verteilte Systeme
- Flexibles Schema — häufig wechselnde Datenstruktur
- Hohe Schreibleistung — IoT, Sensoren, Clickstream
- Unstrukturierte Daten — JSON, Dokumente, Graphen Geeignet für: Projekte mit Dokumentenarbeit, wo riesige Datenmengen verarbeitet werden müssen (z.B. weiß ich, dass VK Video Cassandra als DB verwendet), Datenstruktur ändert sich häufig
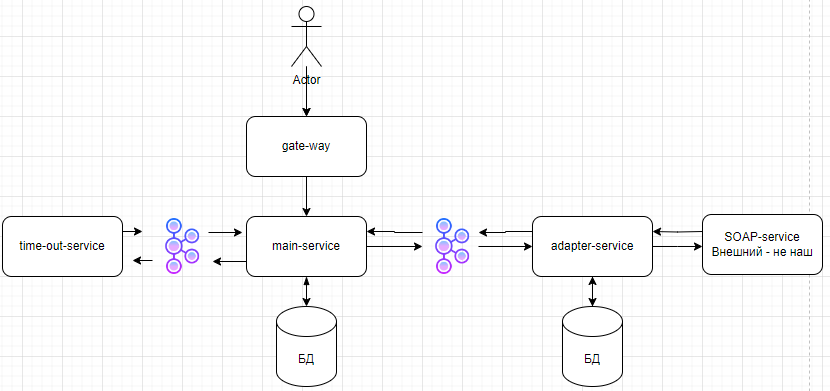
16. System-Design-Aufgabe
Wir arbeiten in einer Versicherungsgesellschaft und bieten Kunden Policen-Services an. Wenn eine Anfrage vom Kunden kommt, müssen wir ein externes SOAP-System über HTTP abfragen, um notwendige Daten für Berechnungen zu erhalten. Laut Anforderungen müssen wir dem Kunden innerhalb von zwei Minuten antworten. Wenn Berechnung in dieser Zeit nicht abgeschlossen ist — müssen wir Fehler zurückgeben.
Problem ist, dass dieses externe SOAP-System im Durchschnitt etwa 40 Sekunden antwortet, aber instabil arbeitet: manchmal sehr langsam, manchmal antwortet überhaupt nicht. Gleichzeitig erwartete Last — bis zu 15.000 Anfragen pro Sekunde, d.h. System muss hohen Anfragestrom aushalten und nicht von dessen Instabilität abhängen.
Ich sage gleich, in dieser Aufgabe gibt es keine klare einzige Antwort. Ich erzähle meine Antwort:
Antwort
Ich gehe der Reihe nach:
- Ich würde Gateway-Schleuse für Autorisierung und Authentifizierung des Benutzers machen (OAuth, Keycloak)
- Asynchrones Modell (Event-Architektur) - SOAP-System ist instabil, gibt Antwort +-40 Sek, SLA ≤ 2 Minuten - asynchroner Ansatz ist maximal gerechtfertigt. Kunde muss nicht warten - Sie geben taskId und er prüft Status
- Microservice-Architektur, ich habe mehrere Services hervorgehoben:
- Main-Service - nur Business-Logik: Task-Erstellung, Status-Speicherung, Orchestration.
- Adapter-Service - Arbeit mit externem System, Retries, Circuit Breaker.
- Timeout-Service - nur Timer und SLA. (Ich würde Delay Queue zur Timer-Verfolgung verwenden)
- Gateway-Service - Autorisierung, Authentifizierung, Benutzerweiterleitung
- In Adapter-Service sind Retries, Circuit Breaker, Fallback benötigt
- Main-Service verarbeitet gesamte Logik, hört auch Antwort von Adapter-Service und Timeout-Service + Main speichert Info über Nachrichten (Outbox-Tabelle)
- Timeout-Service kann mit Delay Queue zur Timer-Verfolgung implementiert werden
- Wir verwenden Kafka + Outbox + De-Dup-Tabelle, um Zustellung und Verarbeitung 1 Mal zu garantieren.
- Outbox garantiert Event-Zustellung.
- Nachrichten-IDs — Schutz vor Duplikaten im Consumer.
- Kafka — hält deinen TPS mit riesiger Reserve aus.
- Für Zustandsverfolgung kann Distributed Tracing verwendet werden
- Archiv-Topic (Fan-out Topic) - wir werfen Nachrichten in separates Topic, das momentan niemand hört, damit Möglichkeit besteht, sich zu verbinden und alle Nachrichten zu hören, selbst wenn Kafka sie bereits aus anderem Topic gelöscht hat. (Dies kann gemacht werden, wenn zukünftig Service-Hinzufügung-Verarbeitung sichtbar ist und dafür zusätzliche Ressourcen vorhanden sind)
- Wenn zukünftig Kundenwachstum sichtbar ist, können Kafka Streams für Arbeit mit großen Daten verwendet werden
Nachteile dieses Ansatzes:
- komplexeres Logging
- komplexere Tracing
- Last auf Infrastruktur
- komplexeres Testing
Vorteile dieses Ansatzes:
- Skalierbarkeit
- Flexibilität / Erweiterbarkeit
- Fehlertoleranz
- Hoher Durchsatz
Ungefähres Service-Interaktionsschema:
Fazit
Heute haben wir ein Beispiel eines vollständigen Interviews für Senior Java Developer Position durchlaufen. Natürlich ist dies kein universelles Szenario - jedes Interview hat seine Nuancen. Aber dies ist echte Erfahrung, die ich hatte, und ich habe versucht zu zeigen, welche Fragen und Situationen auftreten können und worauf besondere Aufmerksamkeit gelegt werden sollte. Ich hoffe, dies hilft Ihnen, sich vorzubereiten und selbstbewusster zum Interview zu gehen.