1. Задача на понимание работы наследования
Есть следующий код:
public class First {
protected int count;
public First() {
System.out.println("First");
calculate();
}
public void calculate() {
System.out.println(count);
}
@Override
public int hashCode() {
return 0;
}
}
class Second extends First {
public Second() {
this.count = 5;
System.out.println("Second");
calculate();
}
public void calculate() {
this.count++;
System.out.println(count);
}
@Override
public int hashCode() {
return 0;
}
}
class Main {
public static void main(String[] args) {
Second s = new Second();
}
}Ответ:
First
1
Second
6
Примечание:
- При создании объекта Second s = new Second(); сначала вызывается конструктор родительского класса First
- В конструкторе First()
- System.out.println(“First”) - выводит “First”
- calculate() → вызывает переопределенный метод из класса “Second”
- Затем выполняется конструктор “Second()”
- this.count = 5 → speed становится 5
- System.out.println(“Second”) → выводит “Second”
- calculate() → снова вызывается “Second.calculate()” где идет “count++“
2. Знание контракта между Equals и HashCode
Есть код(классы такие же как и в задаче выше), что он выведет:
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add(new First());
set.add(new Second());
set.add(new Second());
System.out.println("Размер:" + set.size());
}Ответ:
Размер:3
Примечание:
- new First() - добавляется (хэшкод = 0)
- new Second() - проверяется:
- Хэшкод = 0 (совпадает)
equals()по умолчанию сравнивает ссылки → разные объекты → добавляется
- new Second() - еще один новый объект:
- Хэшкод = 0 (совпадает)
equals()сравнивает ссылки → это третий уникальный объект → добавляется Методequals()по умолчанию (из классаObject) сравнивает ссылки на объекты, а не их содержимое. Поэтому каждыйnew Second()создает новый объект с новой ссылкой, и все они считаются разными.
Тут важно отменить, что даже в случае, если hashCode не будет совпадать, то все равно получим Размер:3
Но если мы переопределим equals и hashCode:
@EqualsAndHashCode // в качестве примера взял аннотацию из lombok
public class First {
}
@EqualsAndHashCode
class Second extends First {
}То результат уже будет Size:2
3. Устройство HashMap
Я понимаю, что уже почти в каждом углу говорилось про HashMap. Я расскажу очень коротко(если хотите почитать подробнее и углубиться, то можете посмотреть тут)
Ответ:
HashMap — это массив корзин. Индекс выбираем по hashCode, а столкновения (коллизии) решаем сравнениями через equals.
Алгоритм вставки:
- Считаем hashCode() и определяем корзину.
- Если корзина пуста - вставляем.
- Если в корзине есть элементы:
- ищем тот же ключ через equals
- если найден → заменяем значение
- если нет → добавляем новый элемент (список → дерево при >8 элементов)
- При заполненности > loadFactor происходит resize.
4. Зачем нужны бинарные деревья и их сложность
Про бинарные деревья тоже говорили уже везде, подробная инфа тут
Ответ:
Зачем нужны бинарные деревья: Чтобы хранить данные в отсортированном виде и быстро выполнять поиск, вставку и удаление.
Сложность поиска в BST:
- лучший случай (сбалансировано): O(log n)
- худший случай (вырождено в список): O(n)
Сложность вставки:
- лучший случай: O(log n)
- худший случай: O(n)
5. Какие есть виды GC и в чем их отличие
Об этом я рассказывал тут
Ответ:
Serial GC
- Использует один поток для всех фаз GC.
- Подходит для однопоточных приложений и небольших heap.
- Алгоритм: “copying” (в Young Gen) и “mark-sweep-compact” (в Old Gen).
- Параметр: -XX:+UseSerialGC
Parallel GC (Throughput Collector)
- Использует несколько потоков для работы в Young и Old Gen.
- Цель — максимальная пропускная способность, а не минимизация пауз.
- Подходит для серверных приложений без строгих требований к задержкам.
- Параметр: -XX:+UseParallelGC
CMS (Concurrent Mark Sweep) [устарел]
- Работает параллельно с приложением (concurrent), уменьшая stop-the-world паузы.
- Этапы: initial mark, concurrent mark, remark, sweep.
- Не компактизирует память (может привести к фрагментации).
- Устарел начиная с Java 9 и удалён в Java 14
- Параметр: -XX:+UseConcMarkSweepGC
G1 GC (Garbage First)
- Делит heap на множество регионов.
- Каждый регион может быть частью Young или Old Generation.
- Этапы GC включают: Initial Mark, Concurrent Mark, Remark, Cleanup, Copy.
- Работает по принципу “сборка сначала самых мусорных регионов” (Garbage First).
- Использует предсказуемые паузы и старается не превышать MaxGCPauseMillis
- Поддерживает инкрементальную, concurrent и компактизирующую сборку Old Gen.
- G1 ведёт статистику “полезности” регионов и выбирает наиболее эффективные для сборки.
- Параметр: -XX:+UseG1GC
- По умолчанию используется с Java 9+
ZGC (Z Garbage Collector)
- Поддерживает heap до терабайт.
- Работает с паузами менее 10 мс, независимо от размера heap.
- Полностью concurrent (почти все фазы выполняются параллельно с приложением).
- Подходит для latency-чувствительных систем.
- Параметр: -XX:+UseZGC
Shenandoah
- Похож на ZGC, с акцентом на короткие паузы.
- Использует concurrent compacting.
- Поддерживается OpenJDK.
- Параметр: -XX:+UseShenandoahGC
6. Типы ссылок в java
Ответ:
Strong Reference (сильная ссылка)
- Это обычные ссылки, которые мы используем каждый день.
- Пока на объект существует хотя бы одна сильная ссылка - он не подлежит сборке мусора.
- Чтобы объект мог быть собран, все сильные ссылки на него должны быть обнулены.
Object obj = new Object();Soft Reference (мягкая ссылка)
- Объект удаляется только при нехватке памяти.
- Используется в кешах, чтобы не загружать память, но сохранить объект, если он ещё полезен.
- Можно получить объект через
ref.get(), но если GC уже удалил его - вернётсяnull.
SoftReference<Object> ref = new SoftReference<>(new Object());Weak Reference (слабая ссылка)
- Объект может быть собран немедленно, даже если только слабые ссылки на него остались.
- Используется для реализации структур с автоудалением (например,
WeakHashMap). - Часто применяется, когда объект должен быть доступен «до тех пор, пока он кому-то нужен».
WeakReference<Object> ref = new WeakReference<>(new Object());Phantom Reference (фантомная ссылка)
- Объект уже помечен как удаляемый, но ещё не собран GC.
- Метод
get()всегда возвращает**null**. - Используется для контроля финализации и освобождения ресурсов вне heap (например, off-heap, native).
- Требует
ReferenceQueue, через которую можно узнать, что объект вот-вот будет удалён.
PhantomReference<Object> ref = new PhantomReference<>(new Object(), referenceQueue);7. Назови 5 классов из пакеты concurrent и зачем они нужны
Ответ
- CompletableFuture - позволяет запускать асинхронные задачи, комбинировать их, цеплять колбэки и работать без блокировок. Упрощает параллелизм.
- ConcurrentHashMap - потокобезопасный HashMap. Позволяет многим потокам одновременно читать и обновлять данные без общего большого локa.
- Phaser - продвинутый синхронизатор, позволяет синхронизировать потоки по фазам (этапам). Гибче, чем CyclicBarrier/CountDownLatch.
- AtomicInteger - примитив для атомарных операций над int без использования локов (CAS). Нужен для счетчиков, флагов и инкрементов между потоками.
- ReentrantLock - явная блокировка с расширенными возможностями: tryLock, fairness, condition-переменные. Более гибкая альтернатива synchronized.
8. Расскажи про DeadLock и LiveLock
Ответ
Deadlock (взаимная блокировка)
Потоки навсегда блокируют друг друга, каждый ждёт ресурс, удерживаемый другим. Итог: система стоит, прогресса нет.
Пример: Поток A держит ресурс 1 и ждёт ресурс 2. Поток B держит ресурс 2 и ждёт ресурс 1.
Как избегать:
- Всегда блокировать ресурсы в одном порядке.
- Использовать таймауты при захвате блокировок (tryLock(timeout)).
- Минимизировать количество одновременно захватываемых блокировок.
Livelock (ожившая блокировка)
Потоки не заблокированы, но бесполезно двигаются, постоянно пытаясь избежать конфликта и мешая друг другу. Итог: система работает, но прогресса тоже нет.
Пример: Два потока уступают друг другу ресурс, отказываются и пытаются снова, но синхронно, и бесконечно.
Как избегать:
- Добавлять рандомные задержки или экспоненциальный бэкофф при повторных попытках.
- Использовать явные таймауты и прекращать попытки через определённое время.
- Пересматривать алгоритм кооперации, чтобы не блокировать друг друга непрерывно.
9. SQL задачка
Есть такая структура БД:
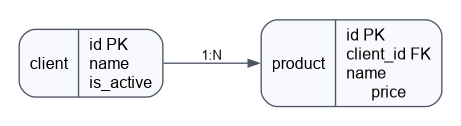 Нужно написать запрос, который вернет имя и общую сумму товаров клиента. Клиент при этом должен быть активным, а сумма товаров больше 0
Нужно написать запрос, который вернет имя и общую сумму товаров клиента. Клиент при этом должен быть активным, а сумма товаров больше 0
Ответ
SELECT c.name AS company_name, SUM(p.price) AS product_sum
FROM client c
JOIN product p ON c.id = p.client_id
WHERE c.is_active
GROUP BY c.id, c.name
HAVING SUM(p.price) > 0
ORDER BY product_sum DESC;10. В чем разница между having и where
Ответ
Время применения
- WHERE - фильтрация до группировки (на уровне отдельных строк)
- HAVING - фильтрация после группировки (на уровне групп) С чем работают
- WHERE - работает с отдельными записями и обычными полями
- HAVING - работает с результатами агрегатных функций (SUM, COUNT, AVG и т.д.) Использование с GROUP BY
- WHERE - может использоваться без GROUP BY
- HAVING - используется вместе с GROUP BY
11. Что такое explain plan и для чего он нужен
Ответ
EXPLAIN PLAN — это план выполнения SQL-запроса, показывающий, какие операции СУБД будет выполнять (сканирование таблицы, использование индекса, типы join’ов и т.д.). Он нужен для понимания того, где находятся узкие места и что можно оптимизировать — например, добавить индекс, поменять тип соединения или переписать запрос.
12. Какие есть уровни изоляции транзакции и какие проблемы в них присутствуют?
Ответ
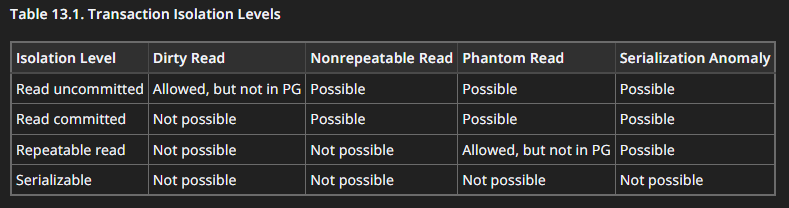 PostgreSQL: Documentation: 18: 13.2. Transaction Isolation
PostgreSQL: Documentation: 18: 13.2. Transaction Isolation
13. Понимание proxy в spring
Есть базовые задачки с транзакциями, но на этом собесе мне задавали вопросы про @Cacheable. Есть примера кода, в котором кэш не работает, как сделать так, чтобы он заработал:
@Service@EnableCaching
public class CacheClass {
@SneakyThrows
@PostConstruct
public void init() {
System.out.println(test(1));
Thread.sleep(1000);
System.out.println(test(2));
Thread.sleep(1000);
System.out.println(test(1));
}
@Cacheable(cacheNames = "test", key = "#integer")
public String test(int integer) {
return LocalDateTime.now().toString();
}
}Ответ
Здесь можно сразу предложить несколько вариантов по аналогии с транзакциями:
- Сделать self inject и вызвать метод через него
- Использовать applicationContext.getBean(CacheClass.class); Для @Transaction это было 100% сработало бы, но в Cacheable есть подводный камень. Ни один из верхних вариантов не сработает. Подумай еще, как можно это решить?
Ответ для Cacheable
Для @Cacheable ситуация ещё хуже: кеш-аспект инициализируется позднее, поэтому вызов @Cacheable из @PostConstruct обычно не срабатывает — об этом есть явное issue в Spring
Тут вы можете применить ApplicationRunner или CommandLineRunner, которые смогу помочь, просто заимплементить его:
@Service
@EnableCaching
public class CacheClass implements ApplicationRunner {
@Autowired
@Lazy
private CacheClass self;
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println(self.test(1));
Thread.sleep(1000);
System.out.println(self.test(2));
Thread.sleep(1000);
System.out.println(self.test(1));
}
@Cacheable(cacheNames = "test", key = "#integer")
public String test(int integer) {
return LocalDateTime.now().toString();
}
}14. Приведите пример каждого из типа паттернов(поведенческий, порождающий, структурный) и назовите ваш самый любимый паттерн и как вы его применяли.
Ответ
 Мой же самый любимый паттерн это шаблонный метод. Шаблонный метод используют, когда есть общий алгоритм, который повторяется у разных обработчиков, но некоторые шаги в нём должны отличаться. Общая логика фиксируется в базовом классе, а изменяющиеся части выносятся в абстрактные методы и уже конкретные реализации определяют, что происходит на этих этапах. Это позволяет избежать дублирования кода и чётко разделить общие и различающиеся шаги алгоритма.
Этот паттерн выручал меня не один раз)
Мой же самый любимый паттерн это шаблонный метод. Шаблонный метод используют, когда есть общий алгоритм, который повторяется у разных обработчиков, но некоторые шаги в нём должны отличаться. Общая логика фиксируется в базовом классе, а изменяющиеся части выносятся в абстрактные методы и уже конкретные реализации определяют, что происходит на этих этапах. Это позволяет избежать дублирования кода и чётко разделить общие и различающиеся шаги алгоритма.
Этот паттерн выручал меня не один раз)
15. Когда использовать реляционные базы, а когда нет. В чем разница между SQL и NoSQL базой
Ответ
SQL БД:
- Сложные запросы и JOIN — когда нужны агрегации и связи между таблицами
- Транзакции ACID — банковские операции, финансовые системы
- Структурированные данные — четкая схема, предсказуемая структура
- Целостность данных — внешние ключи, constraints
- Отчетность и аналитика — сложные SQL-запросы Подходят для: банковские системы (транзакции), медицинские записи (целостность данных), интернет-магазины (заказы, inventory)
NoSQL БД:
- Большие объемы данных — Big Data, логгирование
- Горизонтальное масштабирование — распределенные системы
- Гибкая схема — часто меняющаяся структура данных
- Высокая производительность записи — IoT, сенсоры, clickstream
- Неструктурированные данные — JSON, документы, графы Подходят для: проекты, где работают с документами, где нужно обрабатывать огромные объемы данных(например я знаю, что в VK Video используют cassandra в качестве БД), структура данных часто меняется
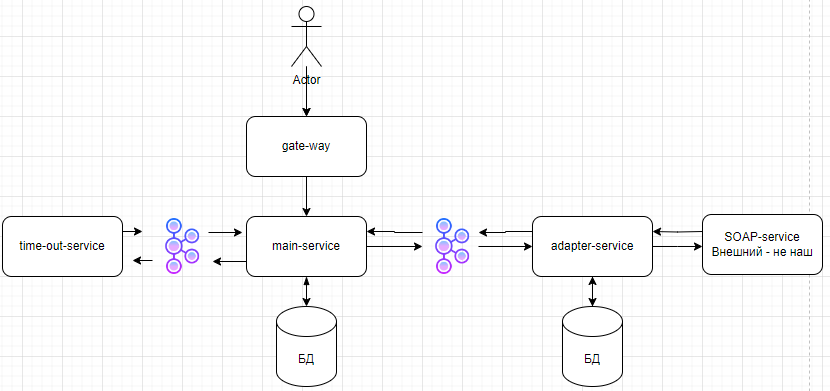
16. Задачка на system design
Мы работаем в страховой компании и предоставляем клиентам услуги по оформлению полисов. Когда приходит запрос от клиента, нам нужно обратиться к сторонней SOAP-системе через HTTP, чтобы получить необходимые данные для расчёта. По требованиям мы должны дать клиенту ответ в течение двух минут. Если за это время расчёт не завершён — мы обязаны вернуть ошибку.
Проблема в том, что эта внешняя SOAP-система в среднем отвечает около 40 секунд, но работает нестабильно: иногда очень медленно, иногда вообще не отвечает. При этом ожидаемая нагрузка — до 15 000 запросов в секунду, то есть система должна выдерживать высокий поток обращений и не зависеть от её нестабильности.
Скажу сразу, в этой задаче нет четкого одного ответа. Я же расскажу свой ответ:
Ответ
Я пойду по порядку:
- Я бы сделал gate-way шлюз для авторизации и аутентификации пользователя(OAuth, Keycloak)
- Асинхронная модель(архитектура событий) - SOAP-система нестабильная, выдает ответ +-40 сек, SLA ≤ 2 минут - асинхронный подход максимально оправдан. Клиенту не нужно ждать - даёте taskId и он проверяет статус
- Микросервисная архитектура, я выделил несколько сервисов:
- Main-service - только бизнес-логика: создание задач, хранение статуса, оркестрация.
- Adapter-service - работа с внешней системой, ретраи, circuit breaker.
- Timeout-service - только таймеры и SLA. (Я бы использовал delay queue для отслеживания таймера)
- Gate-way service - авторизация, аутентификация, переадресация пользователей
- В Adapter-service нужны ретраи, circuit breaker, fallback
- Main-service обрабатывает всю логику, также он прослушивает ответ от adapter-service и timeout-service + main хранит информацию о сообщениях(outbox таблица)
- Timeout-service можно реализовать с помощью delay queue для отслеживания таймера
- Мы будем использовать kafka + outbox + de-dup таблица, чтобы гарантировать доставку и обработку 1 раз.
- Outbox гарантирует доставку события.
- Идентификаторы сообщений — защита от дублей в потребителе.
- Kafka — выдержит твой TPS с огромным запасом.
- Для отслеживания состояний можно использовать distributed tracing
- Архивный топик (fan-out topic) - мы отбрасываем сообщения в отдельный топик, который на данный момент никто не слушает, чтобы была возможность к нему подключиться и прослушать все сообщения, даже, если kafka уже удалила их из другого топика.(Это можно сделать, если в будущем видится добавление сервисов обработки и есть на это доп ресурсы)
- Если в дальнейшем видится рост клиентов, можно использовать Kafka Streams для работы с большими данными
Минусы такого подхода:
- сложнее логирование
- сложнее трассировка
- нагрузка на инфраструктуру
- сложнее тестирование
Плюсы такого подхода:
- масштабируемость
- гибкость / расширяемость
- отказоустойчивость
- высокая пропускная способность
Примерная схема взаимодействия сервисов:
Итог
Сегодня мы прошли через пример полного собеседования на позицию Senior Java Developer. Конечно, это не универсальный сценарий - у каждого интервью свои нюансы. Но это реальный опыт, который был у меня, и я постарался показать, какие вопросы и ситуации могут встретиться, а на что стоит обратить особое внимание. Надеюсь, это поможет вам подготовиться и подойти к собесу более уверенно.