Transaktionen
Eine Transaktion ist eine Reihe von Datenbankoperationen, die vollständig oder überhaupt nicht ausgeführt werden.
ACID
- Atomarität - keine Transaktion wird teilweise im System fixiert
- Konsistenz - eine erfolgreiche Transaktion bringt Daten immer in einen korrekten, zulässigen Zustand
- Isolation - parallele Transaktionen stören sich nicht gegenseitig und arbeiten, als ob sie nacheinander ausgeführt würden
- Dauerhaftigkeit - wenn eine Transaktion committet wurde, sind ihre Daten garantiert gespeichert und verschwinden nicht
Isolationsstufen
Read uncommitted
Sieht committete und nicht committete Daten von Transaktionen.
- PostgreSQL unterstützt faktisch kein “Dirty Read”.
- Alle SELECT sehen nur committete Daten, selbst wenn Read Uncommitted angegeben ist. Dies ist offiziell: In PostgreSQL verhält sich Read Uncommitted wie Read Committed.
Read committed
Jede Operation innerhalb einer Transaktion sieht nur die Daten, die zum Zeitpunkt der Ausführung der spezifischen Abfrage committet wurden, nicht zum Beginn der Transaktion
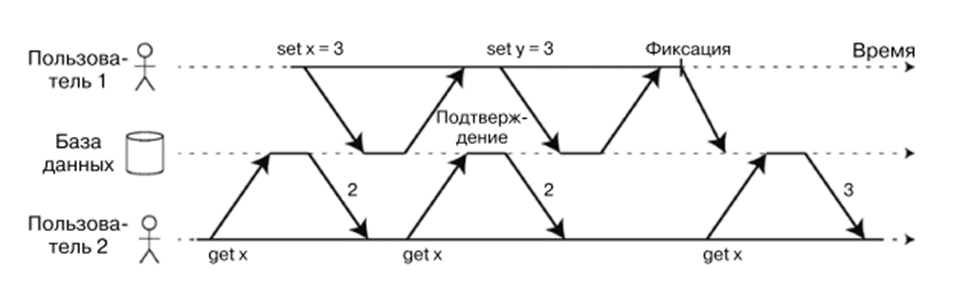
Read committed
Repeatable read
- Zu Beginn der Transaktion macht PostgreSQL einen Snapshot des DB-Zustands.
- Alle nachfolgenden Abfragen dieser Transaktion lesen dasselbe konsistente Bild, unabhängig davon, was andere Transaktionen zwischenzeitlich committet haben.
- Daher gibt es keine Non-Repeatable Reads — dieselbe Auswahl gibt immer die gleichen Daten innerhalb der Transaktion zurück.
- Die Implementierung von Repeatable Read in PostgreSQL verhindert Phantom Reads
Serializable
Sie garantiert, dass selbst bei gleichzeitiger Ausführung von Transaktionen das Ergebnis dasselbe bleibt wie bei ihrer sequentiellen (eine nach der anderen) Ausführung, ohne jegliche Parallelität.
- Lesende Transaktionen stören sich nicht gegenseitig — Sie können ruhig Daten lesen, während jemand anderes sie ändert.
- Parallele Schreibtransaktionen blockieren sich auch nicht gegenseitig, wenn sie mit verschiedenen Objekten arbeiten.
- Blockierung tritt nur dann auf, wenn zwei Transaktionen versuchen, dasselbe Objekt gleichzeitig zu ändern.
Hier ist eine sehr nützliche Tabelle aus der offiziellen Postgres-Dokumentation
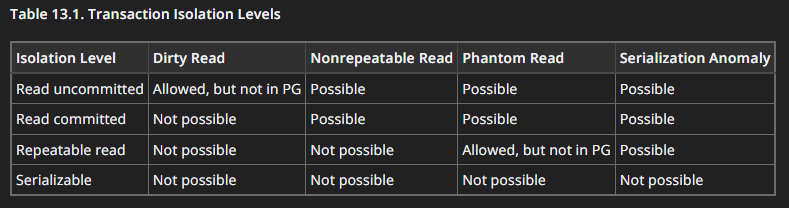
https://www.postgresql.org/docs/current/transaction-iso.html
Indizes
Ein Index ist eine Hilfsstruktur, die zusammen mit der Tabelle gespeichert wird und hilft, benötigte Datensätze schnell zu finden, wodurch die Datenabfrage beschleunigt wird.
Es ist wichtig zu beachten, dass Indizes auch das Hinzufügen, Löschen und Ändern von Daten verlangsamen können, da bei diesen Operationen auch die entsprechenden Indizes aktualisiert werden müssen
Hash-Indizes
Schlüssel-Wert-Speicher funktionieren wie Wörterbücher in Programmiersprachen. Normalerweise werden sie über Hash-Tabellen implementiert, bei denen jedem Schlüssel eine Adresse des Werts in der Datendatei entspricht.
Beim Hinzufügen oder Aktualisieren eines Schlüssel-Wert-Paares wird die Hash-Tabelle aktualisiert, um die korrekte Adresse zu speichern. Und um einen Wert zu lesen, schaut das System einfach die Adresse in der Hash-Tabelle nach und greift auf die Datei zu — schnell und effizient.
SS-Tabellen und LSM-Bäume
Eine SS-Tabelle (SSTable) ist eine Datei, in der Schlüssel sortiert sind und jeder nur einmal vorkommt. Eine solche Struktur erleichtert das Zusammenführen von Segmenten auch großer Dateien, ohne die gesamte Tabelle in den Speicher zu laden, und funktioniert nach dem Prinzip des Merge-Sort.
Um einen benötigten Schlüssel zu finden, ist es nicht notwendig, alle Indizes im Speicher zu halten: es reicht, benachbarte Schlüssel zu kennen und die Datei zwischen ihnen bis zum benötigten Wert zu durchsuchen.
 SS-Tabellen und LSM-Bäume
SS-Tabellen und LSM-Bäume
B-Bäume
Der B-Baum ist die am weitesten verbreitete Indexstruktur. Wie SSTable speichert er Schlüssel-Wert-Paare in sortierter Form, was schnelles Suchen von Schlüsseln und Bereichsabfragen ermöglicht.
Aber im Gegensatz zu SSTable teilt der B-Baum Daten in Seiten fester Größe (normalerweise 4 KB), die einzeln gelesen und geschrieben werden. Jede Seite speichert Schlüssel und Verweise auf Kindseiten und bildet einen Baum. Die Suche beginnt immer bei der Wurzelseite und geht durch Seiten, die für Schlüsselbereiche verantwortlich sind, bis der benötigte Wert gefunden wird.
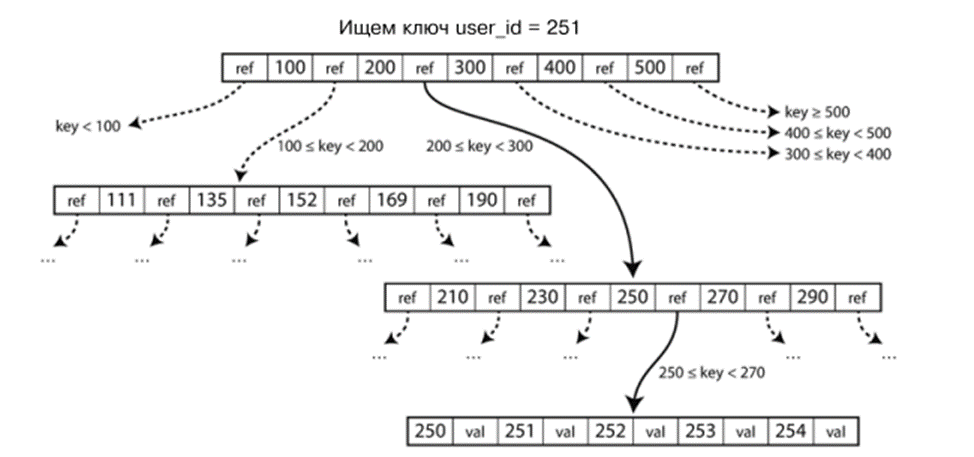
B-Bäume
Unterschied zwischen Indizes (user_id, status) und (user_id) INCLUDE (status)
Zusammengesetzter Index (user_id, status)
-
**Struktur**: Beide Felder sind Teil des Indexschlüssels -
**Sortierung**: Daten werden zuerst nach user_id, dann nach status sortiert -
**Verwendung**: Effizient für -- Abfragen mit Bedingungen auf user_id
- Abfragen mit Bedingungen auf user_id UND status
- Sortierungen nach diesen Feldern
Index mit INCLUDE (user_id) INCLUDE (status)
-
**Struktur**: Nur user_id im Indexschlüssel, status wird in den Blättern des Index gespeichert -
**Sortierung**: Daten werden nur nach user_id sortiert -
**Verwendung**: Effizient für:- Abfragen mit Bedingungen nur auf user_id
- Abfragen, bei denen beide Felder benötigt werden (Covering Index)
- Unterstützt keine Suche/Sortierung nach status allein
Hauptunterschiede
-
Größe: INCLUDE-Index ist normalerweise kompakter -
Flexibilität: Zusammengesetzter Index unterstützt mehr Abfragetypen -
Leistung: Für Abfragen mit Filterung nach beiden Feldern funktioniert der zusammengesetzte Index besser -
Unterstützung: INCLUDE-Syntax ist nicht in allen DBMS verfügbar (erschien in PostgreSQL 11, SQL Server usw.)
Algorithmus zum Hinzufügen von Indizes
Dies ist rein mein Algorithmus, ich sage nicht, dass er der RICHTIGSTE ist und es keine anderen gibt)
Algorithmus zum Hinzufügen von Indizes
- Ziel der Indizierung bestimmen: verstehen, für welche Operationen oder Abfragen der Index verwendet wird. Dies kann beispielsweise die Suche nach einem bestimmten Feld, Sortierung oder Zusammenführung von Daten sein.
- Kosten und Nutzen bewerten: Analyse der aktuellen Datenbankstruktur durchführen und bestimmen, welche Daten und Operationen von der Indizierung profitieren. Kosten für Erstellung und Wartung des Index bewerten.
- Abfrageanalyse: typische Abfragen untersuchen, die in der Datenbank ausgeführt werden, und herausfinden, welche Felder oder Feldkombinationen am häufigsten in WHERE- oder ORDER BY-Bedingungen verwendet werden. Dies hilft zu bestimmen, welche Felder indiziert werden sollten.
- Redundanz vermeiden: das Erstellen von Indizes für jedes Feld ist nicht immer eine effiziente Lösung. Feldkombinationen bestimmen, die häufig in Abfragen verwendet werden, und zusammengesetzte Indizes dafür erstellen.
- Sortierreihenfolge bestimmen: für das Feld, nach dem sortiert oder gruppiert wird, die Reihenfolge bestimmen und einen Index des entsprechenden Typs erstellen.
- Eindeutigkeit bestimmen: wenn das Feld nur eindeutige Werte enthalten soll, einen eindeutigen Index für dieses Feld erstellen.
- Aktualisierung und Wartung des Index: berücksichtigen, dass jede Operation zum Hinzufügen, Aktualisieren oder Löschen von Daten die Indizierung beeinflusst. Die Aktualisierung von Indizes kann Zeit und Ressourcen in Anspruch nehmen, daher ist es wichtig, diesen Prozess zu optimieren.
- Überwachung und Optimierung: regelmäßig die Leistung der Datenbank und Abfragen überwachen. Wenn die Leistung abnimmt, kann die Möglichkeit in Betracht gezogen werden, Indizes zu erstellen oder zu ändern, um die Abfrageausführung zu verbessern.
Replikation
Replikation ist das Kopieren von Daten von einer Datenbank auf andere.
- Wozu: für Fehlertoleranz und hohe Verfügbarkeit.
- Arten: synchron (Daten werden gleichzeitig auf alle Replikate geschrieben) und asynchron (Replikate werden mit Verzögerung aktualisiert).
- Ein Replikat kann zum Lesen verwendet werden, aber Schreibvorgänge gehen an die Master-Datenbank.
Sharding
Sharding ist die horizontale Aufteilung von Daten auf verschiedene Server.
- Jeder Shard enthält einen Teil der Daten (z.B. nach Schlüsselbereich oder Hash).
- Ermöglicht Systemskalierung: Last für Schreib- und Lesevorgänge wird auf mehrere Instanzen verteilt.
Partitionierung
Partitionierung ist die Aufteilung einer Tabelle innerhalb einer Datenbank in logische Teile (Partitionen).
- Zum Beispiel nach Datum: Januar, Februar, März.
- Vereinfacht die Suche und kann einige Abfragen beschleunigen, aber alle Daten bleiben in einer DB, im Gegensatz zum Sharding.
SQL vs NoSQL
SQL (relationale DB)
- Struktur: Tabellen mit festen Spalten und Zeilen.
- Sprache: SQL, strikte Schemas.
- Garantien: ACID, Transaktionen.
- Wann anwenden: komplexe Beziehungen zwischen Daten, strikte Konsistenzanforderungen, Analytik, Banken, ERP.
NoSQL (nicht-relationale DB)
- Struktur: Dokumente, Schlüssel-Wert, Graphen oder spaltenbasierte Speicher.
- Flexible Schemas, horizontale Skalierung ist einfacher.
- Wann anwenden: große Datenmengen, hohe Schreiblast, schnelle Schlüsselsuche, verteilte Systeme, Cache, Logs, IoT.
Wann kann man DB-Denormalisierung verwenden
Denormalisierung ist die bewusste Zusammenführung von Daten, die normalerweise in verschiedenen Tabellen gespeichert werden, um die Anzahl der JOINs zu reduzieren und Abfragen zu beschleunigen.
Wird verwendet, wenn:
- Häufig komplexe Abfragen mit vielen JOINs ausgeführt werden und dies zum Leistungsengpass wird.
- Optimierung für Lesevorgänge in Systemen mit hoher SELECT-Last erforderlich ist.
- Schreibgeschwindigkeit geopfert werden kann zugunsten einer schnelleren Lesegeschwindigkeit (da die Aktualisierung denormalisierter Daten komplexer ist).
VIEW
- Dies ist eine virtuelle Tabelle, die nur die Abfrage speichert, nicht die Daten.
- Daten werden bei jedem Zugriff aus den Basistabellen abgerufen.
- Plus: Bequemlichkeit, Sicherheit, kann komplexe JOINs verbergen.
- Minus: Abfragen können langsamer sein, wenn Basistabellen groß sind.
Materialized VIEW
- Dies ist eine echte Tabelle, die das Abfrageergebnis speichert.
- Zeilen können nicht direkt eingefügt, aktualisiert oder gelöscht werden — Änderungen erfolgen nur durch
REFRESH MATERIALIZED VIEW. - Plus: schneller Zugriff auf Daten, keine Neuberechnung des Ergebnisses bei jeder Abfrage erforderlich.
- Minus: muss periodisch aktualisiert werden, damit Daten aktuell bleiben
Fazit
Heute haben wir Schlüsselaspekte der Arbeit mit Datenbanken behandelt: Tabellenstruktur, Indizes, Transaktionen, Abfragen. All dies kommt häufig in Interviews zu SQL und Arbeit mit DBMS vor. Die Themenliste basiert auf meiner Erfahrung und der Erfahrung von Kollegen, die Interviews für Positionen von Junior bis Senior durchlaufen haben.