Транзакции
Транзакция — это набор операций с базой, который выполняется полностью или совсем не выполняется.
ACID
- Атомарсность - никакая транзакция не будет зафиксирована в системе частично=
- Согласованность - успешная транзакция всегда приводит данные в корректное, допустимое состояние
- Изолированность - параллельные транзакции не мешают друг другу и работают так, будто выполняются по очереди
- Прочность - если транзакция закоммитилась, её данные гарантированно сохранены и не исчезнут
Уровни изоляции
Read uncommitted
Видит зафиксированные и не зафиксированные данные транзакций.
- PostgreSQL фактически не поддерживает “грязное чтение” (dirty read).
- Любые SELECT видят только зафиксированные данные, даже если указан Read Uncommitted. Это официально: в PostgreSQL Read Uncommitted ведёт себя как Read Committed.
Read committed
каждая операция внутри транзакции видит только те данные, которые были зафиксированы к моменту выполнения конкретного запроса, а не к началу транзакции
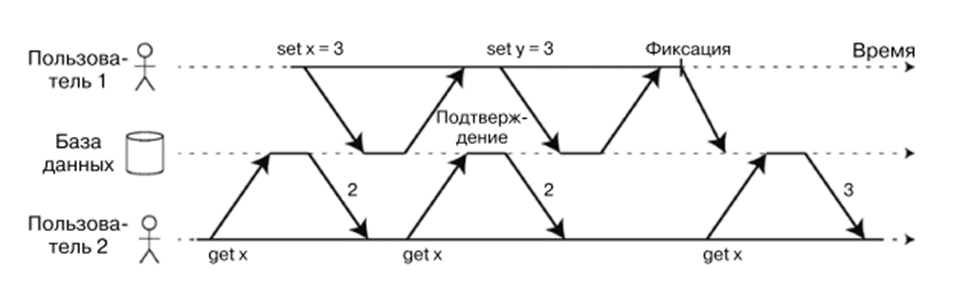
Read committed
Repeatable read
- В начале транзакции PostgreSQL делает снимок состояния БД (snapshot).
- Все последующие запросы этой транзакции читают одну и ту же консистентную картину, независимо от того, что успели закоммитить другие транзакции.
- Поэтому non-repeatable reads отсутствуют — одна и та же выборка всегда возвращает одинаковые данные в рамках транзакции.
- реализация Repeatable Read в PostgreSQL не допускает фантомных чтений
Serializable
Она гарантирует, что даже при конкурентном выполнении транзакций результат останется таким же, как и в случае их последовательного (по одной за раз) выполнения, без всякой конкурентности.
- Читающие транзакции не мешают друг другу — ты можешь спокойно читать данные, пока кто-то другой их меняет.
- Параллельные транзакции записи тоже не блокируют друг друга, если они работают с разными объектами.
- Блокировка возникает только тогда, когда две транзакции пытаются изменить один и тот же объект одновременно.
Вот очень полезная табличка из официальной доки Postgres
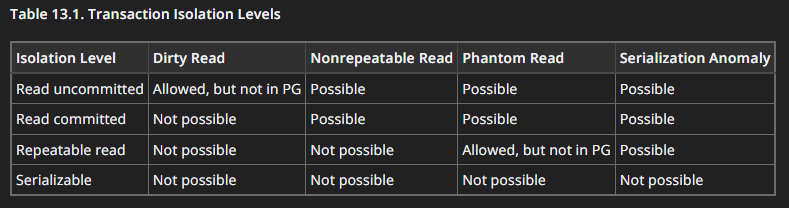
https://www.postgresql.org/docs/current/transaction-iso.html
Индексы
Индекс - это вспомогательная структура, которая хранится вместе с таблицей и помогает быстро находить нужные записи, ускоряя выборку данных.
Важно отметить, что индексы могут также замедлять добавление, удаление и изменение данных, так как при этом операции также требуется обновление соответствующих индексов
Хеш-индексы
Хранилища типа ключ — значение работают как словари в языках программирования. Обычно реализуются через хеш-таблицу, где каждому ключу соответствует адрес значения в файле данных.
При добавлении или обновлении пары «ключ — значение» хеш-таблица обновляется, чтобы хранить правильный адрес. А чтобы прочитать значение, система просто смотрит адрес в хеш-таблице и обращается к файлу — быстро и эффективно.
SS-таблицы и LSM-деревья
SS-таблица (SSTable) — это файл, где ключи отсортированы и каждый встречается только один раз. Такая структура облегчает слияние сегментов даже больших файлов, не загружая всю таблицу в память, и работает по принципу сортировки слиянием.
Чтобы найти нужный ключ, не обязательно держать все индексы в памяти: достаточно знать соседние ключи и просматривать файл между ними до нужного значения.
 SS-таблицы и LSM-деревья
SS-таблицы и LSM-деревья
B-деревья
B-дерево — самая распространённая индексная структура. Как и SSTable, оно хранит пары «ключ — значение» в отсортированном виде, что позволяет быстро искать ключи и выполнять диапазонные запросы.
Но в отличие от SSTable, B-дерево делит данные на страницы фиксированного размера (обычно 4 КБ), которые читаются и записываются по одной. Каждая страница хранит ключи и ссылки на дочерние страницы, формируя дерево. Поиск всегда начинается с корневой страницы и проходит через страницы, отвечающие за диапазоны ключей, пока не найдётся нужное значение.
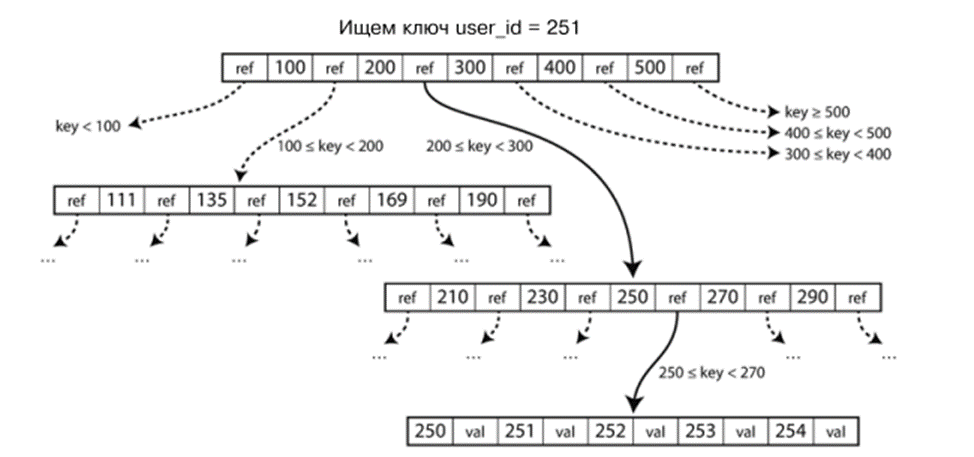
B-деревья
Разница между индексами (user_id, status) и (user_id) INCLUDE (status)
Составной индекс (user_id, status) 1. Структура: Оба поля являются частью ключа индекса 2. Сортировка: Данные сортируются сначала по user_id, затем по status 3. Использование: Эффективен для - - Запросов с условиями на user_id - Запросов с условиями на user_id И status - Сортировок по этим полям
Индекс с INCLUDE (user_id) INCLUDE (status) 1. Структура: Только user_idв ключе индекса, status хранится в листьях индекса 2. Сортировка: Данные сортируются только по user_id 3. Использование: Эффективен для: - Запросов с условиями только на user_id - Запросов, где нужны оба поля (покрывающий индекс) - Не поддерживает поиск/сортировку по status отдельно
Ключевые различия 1. Размер: INCLUDE-индекс обычно компактнее 2. Гибкость: Составной индекс поддерживает больше типов запросов 3. Производительность: Для запросов с фильтрацией по обоим полям составной индекс работает лучше 4. Поддержка: INCLUDE синтаксис доступен не во всех СУБД (появился в PostgreSQL 11, SQL Server и др.)
Алгоритм вешанья индексов
Это чистой мой алгоритм, я не говорю, что он САМЫЙ ВЕРНЫЙ и нет других)
Алгоритм вешанья индексов
- Определить цель индексирования: нужно понять, для каких операций или запросов индекс будет использоваться. Например, это может быть поиск по определенному полю, сортировка или слияние данных.
- Оценить затраты и выгоды: провести анализ текущей структуры базы данных и определить, какие данные и операции будут выигрывать от индексирования. Оценить затраты на создание и поддержку индекса.
- Анализ запросов: изучить типичные запросы, которые будут выполняться в базе данных, и выяснить, какие поля или комбинации полей чаще всего используются в условиях WHERE или ORDER BY. Это поможет определить, какие поля следует индексировать.
- Избегать избыточности: создание индексов для каждого поля не всегда является эффективным решением. Определить комбинации полей, которые часто используются в запросах, и создать составные индексы для них.
- Определить порядок сортировки: для поля, по которому будет выполняться сортировка или группировка, определить порядок и создать индекс соответствующего типа.
- Определить уникальность: если поле должно содержать только уникальные значения, создать уникальный индекс для этого поля.
- Обновление и поддержка индекса: учесть, что каждая операция добавления, обновления или удаления данных влияет на индексирование. Обновление индексов может занимать время и ресурсы, поэтому важно оптимизировать этот процесс.
- Мониторинг и оптимизация: регулярно производить мониторинг производительности базы данных и запросов. Если производительность снижается, можно рассмотреть возможность создания или изменения индексов для улучшения выполнения запросов.
Репликация
Репликация — это копирование данных с одной базы на другие.
- Зачем: для отказоустойчивости и высокой доступности.
- Виды: синхронная (данные пишутся одновременно на все реплики) и асинхронная (реплики обновляются с задержкой).
- Реплика может использоваться для чтения, но запись идёт в мастер-базу.
Шардирование
Шардирование — это горизонтальное деление данных между разными серверами.
- Каждая шард содержит часть данных (например, по диапазону ключей или хешу).
- Позволяет масштабировать систему: нагрузка на запись и чтение распределяется между несколькими инстансами.
Секционирование
Секционирование — это деление таблицы внутри одной базы на логические части (секции).
- Например, по дате: январь, февраль, март.
- Упрощает поиск и может ускорять некоторые запросы, но все данные остаются в одной БД, в отличие от шардирования.
SQL vs NoSQL
SQL (реляционные БД)
- Структура: таблицы с фиксированными колонками и строками.
- Язык: SQL, строгие схемы (schema).
- Гарантии: ACID, транзакции.
- Когда применять: сложные связи между данными, строгие требования к консистентности, аналитика, банки, ERP.
NoSQL (нереляционные БД)
- Структура: документы, ключ‑значение, графы или колоночные хранилища.
- Гибкие схемы, горизонтальное масштабирование проще.
- Когда применять: большие объёмы данных, высокая нагрузка на запись, быстрый поиск по ключу, распределённые системы, кэш, логи, IoT.
Когда можно использовать денормализацию бд
Денормализация — это сознательное объединение данных, которые обычно хранятся в разных таблицах, чтобы уменьшить количество соединений (JOIN) и ускорить запросы.
Используют, когда:
- Часто выполняются сложные запросы с большим количеством JOIN, и это становится узким местом по производительности.
- Нужна оптимизация чтения в системах с высокой нагрузкой на SELECT.
- Можно пожертвовать скоростью записи ради ускорения чтения (так как обновление денормализованных данных сложнее).
VIEW
- Это виртуальная таблица, которая хранит только запрос, а не данные.
- Данные берутся из базовых таблиц каждый раз при обращении.
- Плюс: удобство, безопасность, можно скрыть сложные JOIN’ы.
- Минус: запросы могут быть медленнее, если базовые таблицы большие.
Materialized VIEW
- Это настоящая таблица, которая хранит результат запроса.
- Нельзя вставлять, обновлять или удалять строки напрямую — изменения происходят только через
REFRESH MATERIALIZED VIEW. - Плюс: быстрый доступ к данным, не нужно пересчитывать результат при каждом запросе.
- Минус: нужно периодически обновлять, чтобы данные оставались актуальными
Итог
Сегодня мы рассмотрели ключевые аспекты работы с базами данных: структуру таблиц, индексы, транзакции, запросы. Все это часто встречается на собеседованиях по SQL и работе с СУБД. Список тем составлен на основе моего опыта и опыта коллег, проходивших собеседования на позиции от Junior до Senior.